

1.以下代碼僅供學(xué)習(xí)交流,主要功能是抓取抖音用戶主頁視頻-喜歡視頻-合集視頻(只支持公開用戶)
2.程序運(yùn)行后,會在當(dāng)前目錄下生成video文件夾來存儲抓取的視頻。
import os
import requests
from bs4 import BeautifulSoup
# 初始化文件夾
def ini():
# 判斷video文件夾是否存在
if not os.path.exists('video'):
os.mkdir('video')
# 判斷主頁文件夾是否存在
if not os.path.exists('video/主頁'):
os.mkdir('video/主頁')
# 判斷喜歡文件夾是否存在
if not os.path.exists('video/喜歡'):
os.mkdir('video/喜歡')
# 判斷合集文件夾是否存在
if not os.path.exists('video/合集'):
os.mkdir('video/合集')
# 鏈接重定向
def redirect(url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=header)
return response.url
# 替換標(biāo)題中的特殊字符
def replace(title):
title = title.replace('\\', '')
title = title.replace('/', '')
title = title.replace(':', '')
title = title.replace('*', '')
title = title.replace('?', '')
title = title.replace('"', '')
title = title.replace('<', '')
title = title.replace('>', '')
title = title.replace('|', '')
title = title.replace('\n', '')
return title
def operate():
operation = input('是否繼續(xù)爬取?(y/n)')
if operation == 'y':
start()
elif operation == 'n':
exit()
def start():
while True:
print('===========================')
print('1. 作者主頁視頻')
print('2. 點(diǎn)贊頁面視頻')
print('3. 作者合集視頻')
print('===========================')
Type = input('請輸入爬取的視頻類型:')
if Type == '1':
home()
break
elif Type == '2':
like()
break
elif Type == '3':
collection()
break
else:
print('輸入錯誤,請重新輸入!')
def home():
url = input('請輸入作者分享鏈接:')
# 重定向
url = redirect(url)
sec_uid = url.split('user/')[1].split('?')[0]
# 初始化游標(biāo)
max_cursor = 0
# 初始化視頻數(shù)量
quantity = 0
# 成功下載的視頻數(shù)量
success = 0
# 失敗下載的視頻數(shù)量
error = 0
# 請求頭設(shè)置
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 開始爬取
while True:
# 獲取視頻列表
url = f'https://m.douyin.com/web/api/v2/aweme/post/?reflow_source=reflow_page&sec_uid={sec_uid}&count=21&max_cursor={max_cursor}'
response = requests.get(url, headers=header)
data = response.json()
# 獲取視頻列表
aweme_list = data['aweme_list']
for aweme in aweme_list:
# 更新視頻數(shù)量
quantity += 1
# 獲取視頻標(biāo)題
desc = aweme['desc']
# 獲取作者名稱
author = aweme['author']['nickname']
# 獲取視頻鏈接
video_url = aweme['video']['play_addr']['url_list'][0]
# 判斷作者文件夾是否存在
if not os.path.exists(f'video/主頁/{author}'):
os.mkdir(f'video/主頁/{author}')
# 替換標(biāo)題中的特殊字符
desc = replace(desc)
# 判斷視頻標(biāo)題是否為空,為空則使用視頻quantity+作者名稱作為視頻標(biāo)題
if desc == '':
desc = f'{quantity}{author}'
# 下載提示
print(f'正在下載第{quantity}個視頻:{quantity}.{desc}')
# 超時(shí)處理
try:
# 開始下載
with open(f'video/主頁/{author}/{quantity}_{desc}.mp4', 'wb') as f:
f.write(requests.get(video_url).content)
# 下載成功
success += 1
except WindowsError:
# 下載失敗
error += 1
ns = input(f'第{quantity}個視頻下載失敗,是否繼續(xù)下載?(y/n)')
if ns == 'y':
continue
elif ns == 'n':
exit()
# 判斷是否還有下一頁
if data['has_more']:
# 更新游標(biāo)
max_cursor = data['max_cursor']
else:
# 沒有下一頁則結(jié)束程序
print('視頻下載完成,累計(jì)下載視頻數(shù)量:', quantity, '成功下載視頻數(shù)量:', success, '失敗下載視頻數(shù)量:', error)
operate()
def like():
url = input('請輸入作者分享鏈接:')
# 重定向
url = redirect(url)
sec_uid = url.split('user/')[1].split('?')[0]
# 初始化游標(biāo)
max_cursor = 0
# 初始化視頻數(shù)量
quantity = 0
quantity = 0
# 成功下載的視頻數(shù)量
success = 0
# 失敗下載的視頻數(shù)量
error = 0
# 請求頭設(shè)置
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 獲取收藏者信息
url = f'https://www.iesdouyin.com/web/api/v2/user/info/?sec_uid={sec_uid}'
response = requests.get(url, headers=header)
data = response.json()
# 獲取收藏者名稱
nickname = data['user_info']['nickname']
# 開始爬取
while True:
url = f'https://m.douyin.com/web/api/v2/aweme/like/?reflow_source=reflow_page&sec_uid={sec_uid}&count=21&max_cursor={max_cursor}'
response = requests.get(url, headers=header)
data = response.json()
# 獲取視頻列表
aweme_list = data['aweme_list']
for aweme in aweme_list:
# 更新視頻數(shù)量
quantity += 1
# 獲取視頻標(biāo)題
desc = aweme['desc']
# 獲取視頻鏈接
video_url = aweme['video']['play_addr']['url_list'][0]
# 判斷收藏者文件夾是否存在
if not os.path.exists(f'video/喜歡/{nickname}'):
os.mkdir(f'video/喜歡/{nickname}')
# 替換標(biāo)題中的特殊字符
desc = replace(desc)
# 判斷視頻標(biāo)題是否為空,為空則使用視頻quantity+收藏者名稱作為視頻標(biāo)題
if desc == '':
desc = f'{quantity}{nickname}'
# 下載提示
print(f'正在下載第{quantity}個視頻:{desc}')
# 超時(shí)處理
try:
# 開始下載
with open(f'video/喜歡/{nickname}/{quantity}_{desc}.mp4', 'wb') as f:
f.write(requests.get(video_url).content)
# 下載成功
success += 1
except WindowsError:
# 下載失敗
error += 1
ns = input(f'第{quantity}個視頻下載失敗,是否繼續(xù)下載?(y/n)')
if ns == 'y':
continue
elif ns == 'n':
exit()
# 判斷是否還有下一頁
if data['has_more']:
# 更新游標(biāo)
max_cursor = data['max_cursor']
else:
# 沒有下一頁則結(jié)束程序
print('視頻下載完成,累計(jì)下載視頻數(shù)量:', quantity, '個,成功下載:', success, '個,失敗下載:', error, '個')
operate()
def collection():
url = input('請輸入合集分享鏈接:')
# 重定向
url = redirect(url)
mix_id = url.split('detail/')[1].split('/')[0]
# 初始化游標(biāo)
max_cursor = 0
# 初始化視頻數(shù)量
quantity = 0
# 成功下載的視頻數(shù)量
success = 0
# 失敗下載的視頻數(shù)量
error = 0
# 請求頭設(shè)置
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 獲取合集信息
url = f'https://www.iesdouyin.com/share/mix/detail/{mix_id}'
response = requests.get(url, headers=header)
data = response.text
# 獲取合集信息
soup = BeautifulSoup(data, 'html.parser')
# 獲取合集名稱
collection_name = soup.select('span[class="mix-info-name-text"]')[0].text
# 開始爬取
while True:
url = f'https://www.iesdouyin.com/web/api/mix/item/list/?reflow_source=reflow_page&mix_id={mix_id}&count=10&cursor={max_cursor}'
response = requests.get(url, headers=header)
data = response.json()
# 獲取視頻列表
aweme_list = data['aweme_list']
for aweme in aweme_list:
# 更新視頻數(shù)量
quantity += 1
# 獲取視頻標(biāo)題
desc = aweme['desc']
# 獲取作者名稱
nickname = aweme['author']['nickname']
# 獲取視頻鏈接
video_url = aweme['video']['play_addr']['url_list'][0]
# 判斷作者文件夾是否存在
if not os.path.exists(f'video/合集/{nickname}'):
os.mkdir(f'video/合集/{nickname}')
# 判斷合集文件夾是否存在
if not os.path.exists(f'video/合集/{nickname}/{collection_name}'):
os.mkdir(f'video/合集/{nickname}/{collection_name}')
# 替換標(biāo)題中的特殊字符
desc = replace(desc)
# 判斷視頻標(biāo)題是否為空,為空則使用視頻quantity+作者名稱作為視頻標(biāo)題
if desc == '':
desc = f'{quantity}{nickname}'
# 下載提示
print(f'正在下載第{quantity}集:{desc}')
# 更新視頻標(biāo)題
desc = f'【第{quantity}集】 {desc}'
# 超時(shí)處理
try:
# 開始下載
with open(f'video/合集/{nickname}/{collection_name}/【第{quantity}集】{desc}.mp4', 'wb') as f:
f.write(requests.get(video_url).content)
# 下載成功
success += 1
except WindowsError:
# 下載失敗
error += 1
ns = input(f'第{quantity}集下載失敗,是否繼續(xù)下載?(y/n)')
if ns == 'y':
continue
elif ns == 'n':
exit()
# 判斷是否還有下一頁
if data['has_more']:
# 更新游標(biāo)
max_cursor = data['cursor']
else:
# 沒有下一頁則結(jié)束程序
print('視頻下載完成,累計(jì)下載視頻數(shù)量:', quantity, '個,成功下載:', success, '個,失敗下載:', error, '個')
operate()
if __name__ == '__main__':
ini()
start()
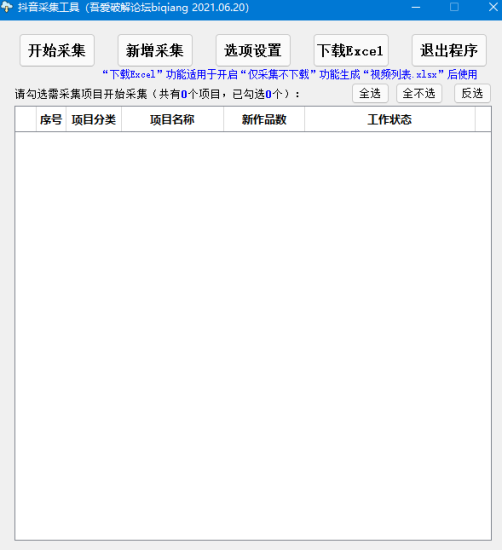
軟件使用教程
![圖片[1]-爬取抖音視頻-主頁-喜歡-合集-軟件分享](http://m.oilmaxhydraulic.com.cn/wp-content/uploads/2022/12/0e247f06e7135001-1024x566.jpg)
![圖片[2]-爬取抖音視頻-主頁-喜歡-合集-軟件分享](http://m.oilmaxhydraulic.com.cn/wp-content/uploads/2022/12/7d1459bc61135012-1024x566.jpg)
![圖片[3]-爬取抖音視頻-主頁-喜歡-合集-軟件分享](http://m.oilmaxhydraulic.com.cn/wp-content/uploads/2022/12/18df20de9e135149.jpg)
![圖片[4]-爬取抖音視頻-主頁-喜歡-合集-軟件分享](http://m.oilmaxhydraulic.com.cn/wp-content/uploads/2022/12/df335b0747135202.jpg)
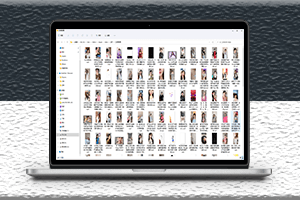
抓取視頻展示
![圖片[5]-爬取抖音視頻-主頁-喜歡-合集-軟件分享](http://m.oilmaxhydraulic.com.cn/wp-content/uploads/2022/12/63a8f2d5d3135101-1024x211.jpg)
![圖片[6]-爬取抖音視頻-主頁-喜歡-合集-軟件分享](http://m.oilmaxhydraulic.com.cn/wp-content/uploads/2022/12/9f0db6efb3135114-1024x555.png)
免費(fèi)資源
? 版權(quán)聲明
THE END





暫無評論內(nèi)容